Please check out the video HERE in case of issues with GFW.
The real-time event-based deblurring system with our proposed method. Contributed by Xiaolei Gu, Xiao Jin (Jiaxing Research Institute, Zhejiang University), Yuhan Bao (Zhejiang University).
From left to right: blurry image, deblurred image, visualized events.
Any potential collaboration on applications is welcomed by contacting me through email.
Abstract
Traditional frame-based cameras inevitably suffer from motion blur due to long exposure times. As a kind of bio-inspired camera, the event camera records the intensity changes in an asynchronous way with high temporal resolution, providing valid image degradation information within the exposure time.
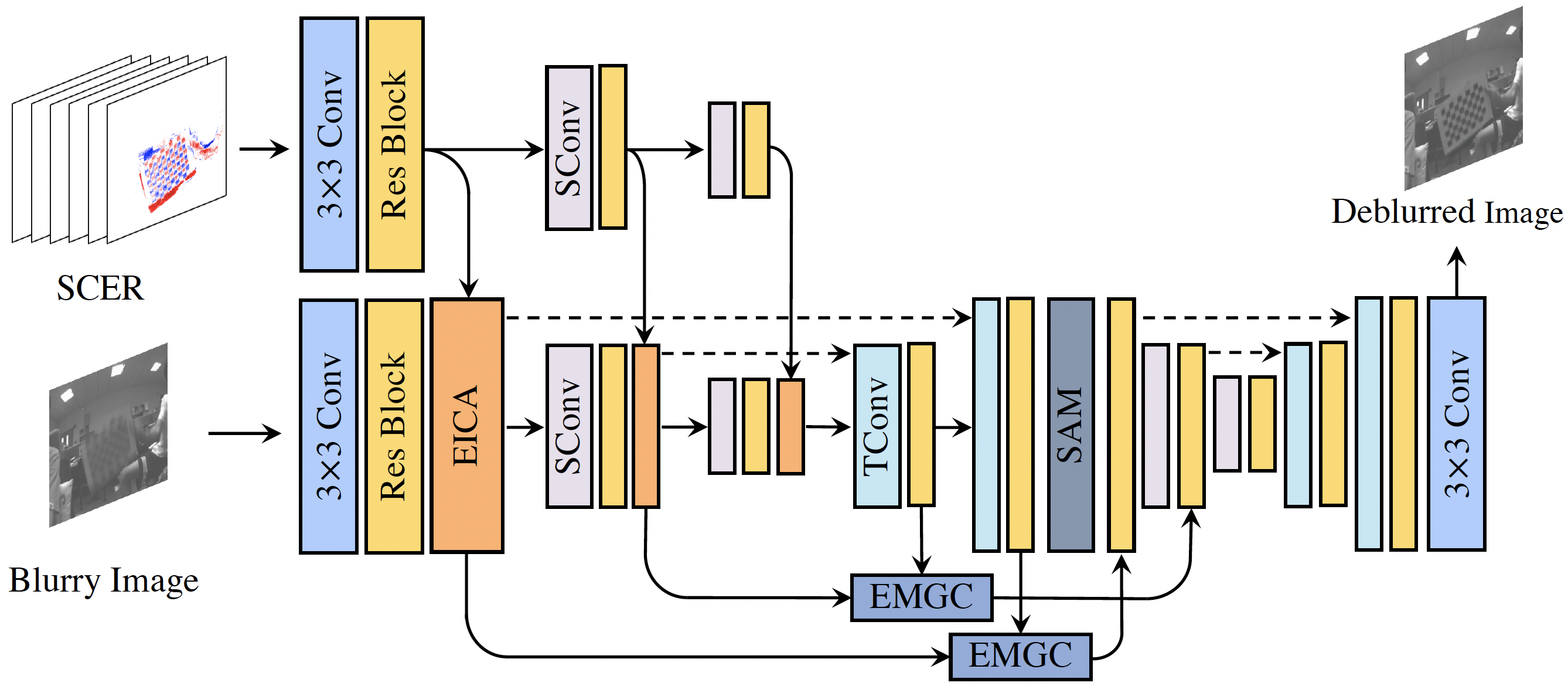
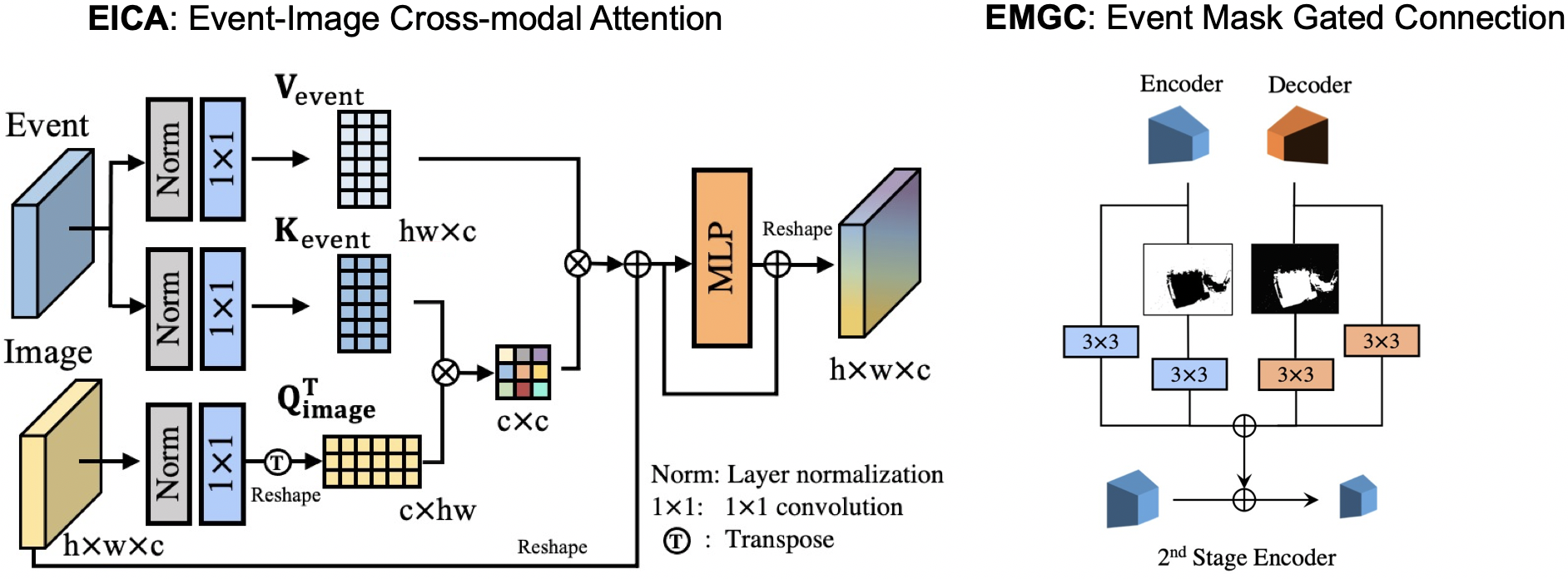
In this work, We rethink the event-based image deblurring problem and unfold it into an end-to-end two-stage image restoration network. To effectively fuse event and image features, we design an event-image cross-modal attention module applied at multiple levels of our network, which allows to focus on relevant features from the event branch and filter out noise.
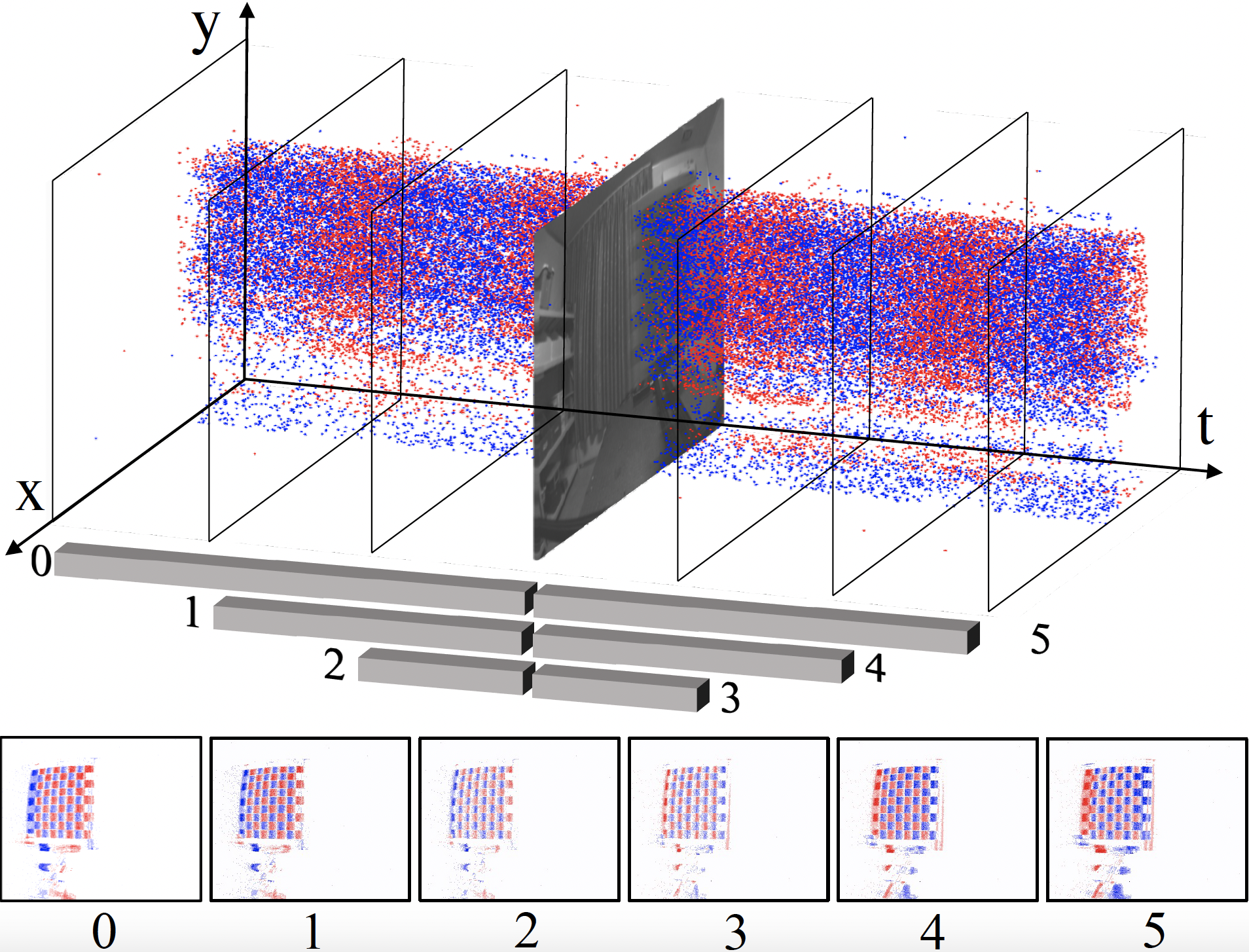
We also introduce a novel symmetric cumulative event representation specifically for image deblurring as well as an event mask gated connection between the two stages of our network which helps avoid information loss. At the dataset level, to foster event-based motion deblurring and to facilitate evaluation on challenging real-world images, we introduce the Real Event Blur (REBlur) dataset, captured with an event camera in an illumination controlled optical laboratory.
Our Event Fusion Network (EFNet) sets the new state of the art in motion deblurring, surpassing both the prior best-performing image-based method and all event-based methods with public implementations on the GoPro dataset (by up to 2.47dB) and on our REBlur dataset, even in extreme blurry conditions.
Qualitative Results
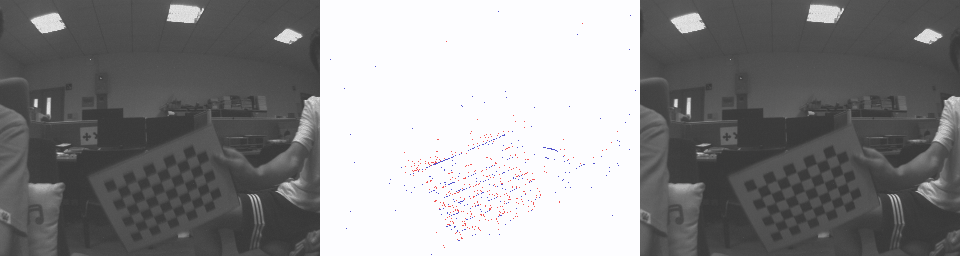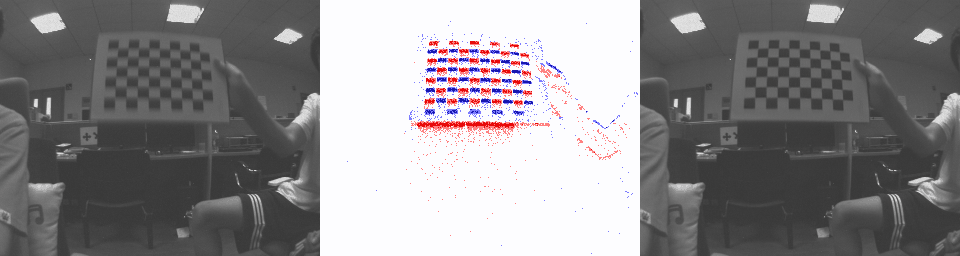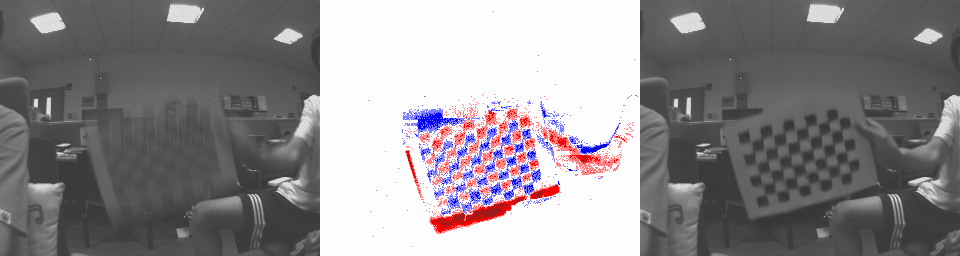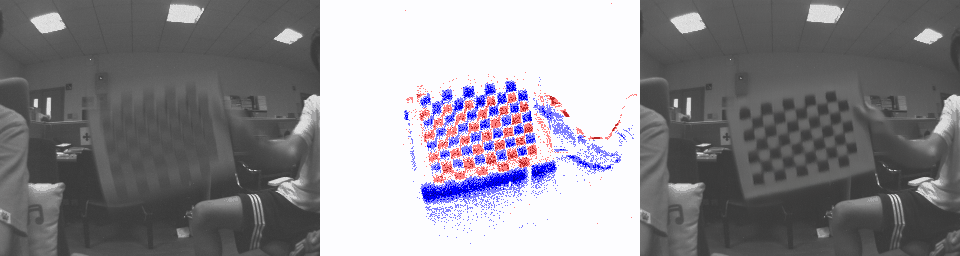
GoPro
Blurry image Each Channel in SCER Result



REBlur
Blurry image Each Channel in SCER Result

BibTeX
@inproceedings{sun2022event,
author = {Sun, Lei and Sakaridis, Christos and Liang, Jingyun and Jiang, Qi and Yang, Kailun and Sun, Peng and Ye, Yaozu and Wang, Kaiwei and Van Gool, Luc},
title = {Event-Based Fusion for Motion Deblurring with Cross-modal Attention},
booktitle = {European Conference on Computer Vision (ECCV)},
year = 2022
}